You're reading for free via Mohit Mayank's Friend Link. Become a member to access the best of Medium.
Member-only story
Generating images using text: The dawn of the AI dreamers
Briefly theoretical and mostly practical examples of creating psychedelics images using text prompts

Introduction
Over the past couple of years, there has been a lot of research and developments into creating AI models that can generate images from a given text prompt. This could be thought of as a personal artist, who tries to create an artwork by following the very words of your instruction. Now, who wouldn't want to have a personal Picasso, but as that's impossible, we can settle with the next very possible thing — an AI Picasso 😃. Tag along, as we understand a unique type of models, in terms of what they are made of and why they work. Next, we will see some examples of the images that I generated and finally conclude with shedding some light on how you can create images of your own!
Theory — what is it?
For this article, we are going to use CLIP + {GAN} family of models. At the very heart of these models is a GAN i.e. Generative Adversarial Networks. It is a combination of two sub-modules, (1) Generator: which tries to create a realistic artificial image, and (2) Discriminator: which tries to distinguish between the artificial/fake and real image. While training GANs, we train both of the sub-modules and over time they become exceptionally good at their job. For us, the generator is an interesting piece, as it has now learned to create very realistic images!

Over the years, there has been a lot of development on improving the performance of GANs. The architecture shared above is very generic and can be considered as a very basic GAN. Recently, people have developed much better architecture, some of them are, (detailed comparison of different types of GANs and code can be found here.)
- ProGAN: where first, the generator and discriminator are trained on low-resolution images and then new layers are added incrementally to handle higher resolutions.
- BigGAN: it mostly follows the architecture of SAGAN, which incorporates attention layers. And as the name suggests, it's a bigger version of SAGAN, with twice as much channel size and 8 times the batch size.
- VQGAN: considered the SotA at the time of writing, it incorporates transformers (which is widely tested in the text domain) with CNN (widely used in the image domain). The final product has more expressive power locally (due to CNN) and globally (due to transformers).
The next important component is the CLIP model which, given a set of captions, basically finds the best matching caption for an image. For this, it has a sub-module that computes the similarity between an image and a text description. After exhaustive training, this module has a lot of expressive power.

The final image generating solution can be created by making a combination of CLIP and a GAN (you can pick one from above), in this manner — (1) use GAN to generate an image, (2) use CLIP to find the similarity between the text prompt and the image, (3) over multiple steps, train the combined models to maximize the similarity score generated by CLIP. In this way, we can think of CLIP as the teacher which gives the student (GAN), homework to draw an image (the only hint given by the teacher is some textual description). The student first returns with a very bad drawing, on which the teacher provides some feedback. The student goes back and later returns with a better version. These interactions (iterations) are nothing but passing and processing of feedbacks between the teacher (CLIP) and student (GAN). Over time, the images become better and we can stop when we think the results are good enough.
Examples
We will follow a bottom-up approach. So we will first look at the images I have generated and then later talk about the practical aspects. While the type of images we can generate is infinite (as it depends on the text prompts), for this article, I tried to broadly generate images over three areas— (1) Painting, (2) Posters, and (3) Entities. For each of these types, I have added some type-specific suffix in the prompts to convey my intentions to the model. We will discuss the text prompts in detail later, so enough talk for now, let us look at some of the images that can be generated using nothing but a google colab notebook and text prompts,
Paintings
- For the very first piece, I used the prompt:
“Queen of Egypt facing defeat with the assistance of King Solomon; landscape epic deviantart”. Have a look at the generated image below. Notice how the model process Egypt by drawing sand dunes and some weird pyramid structure on the right. Also, the mysterious things in the middle seem to be wearing golden clothes and crowns, maybe because of King and Queen text in the prompt. 👑

- Prompt for the next piece is:
“Knights in Black Armour fighting with sorcerers; oil painting; 4k”Notice how adding oil painting in the prompt drastically changed the style of the output. 🧙
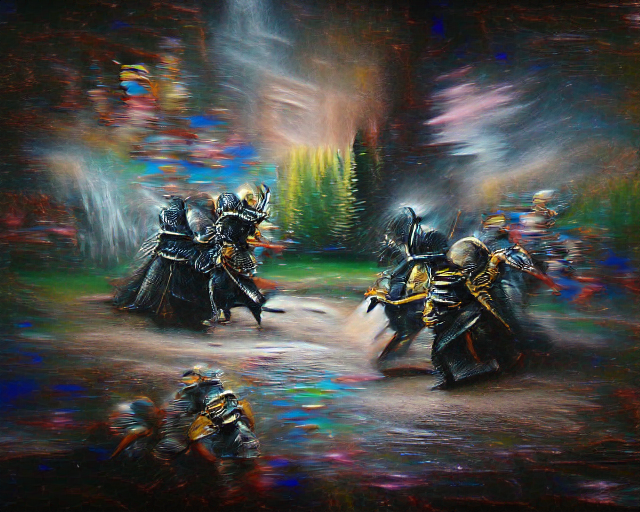
- Prompt for this piece:
“archangels Raphael and Michael cast the evil eye on him; fresco”. Using fresco in the prompt changed the style again. 🏰

Posters
- Prompt for this piece:
“Harry Potter and the Stoned Philosopher | a book poster | ultrarealistic | trending in artstation”Those white things — is it beard or smoke?😆

- Prompt for the piece:
“A man with a gun, a woman and few cars in the background; movie poster; artstation”Well, I said few, not lots of cars 😃

- Prompt for this piece:
“two guys with what looks like some kind of supernatural power; game poster; trending in artstation”🕹️

Entities
- Prompt for this piece:
“Shiva the destroyer god | 4k | trending in artstation”🕉️

- Prompt for this piece:
“a unicorn wearing a black armor | 4k | deviantart | artstation”That's trippy 🦄

- Prompt for this piece:
“a talking tree saying groot; rendered in unreal engine”That’s not Groot 🦸

Videos
The AI model generates images in multiple iterations. So we can save the image from each iteration step and finally club all of them together to create a video. This video will showcase the journey of an image from the initial blank stage to its final artistic stage.
- Let’s try a completely new piece:
“the chimney of the sacred art gallery by James Gurney”🎨

- How about one of the images from above? Picking the movie poster example of guns and cars,

Create your own images
Finally, let us move to the practical aspect where we will discuss how you can create your own images. Please note, I am not the creator of the code shared below. I am just the user, in fact, I am a messenger who is trying to share this cool project with the world. Hmm…I wonder how AI will visualize this! 😉

Sources
There are lots of open-source code material you can follow to create your own images. Note, a lot of these are very experimental in nature, so you may have to play around with a couple and see which one gives better results (read, suites you better). That said, any one of them are good on their own and generates a wide variety of interesting images. Below, I will share some of the excellent works I follow and have used to generate the images/videos I shared before.
- My first suggestion will be VQGAN-CLIP, it's a Github repo created by nerdyrodent. It provides very good documentation and several intuitive examples of different types of images that can be generated using the code. Once you have download and installed the model, generating an image is as simple as,
python generate.py -p "A painting of an apple in a fruit bowl"
- If you are more into google colab (and want to directly jump into the code), you can look into this notebook. Credit where it's due, taking the excerpt from the notebook,
[It was] Originally made by Katherine Crowson (https://github.com/crowsonkb, https://twitter.com/RiversHaveWings). The original BigGAN+CLIP method was by https://twitter.com/advadnoun. Added some explanations and modifications by Eleiber#8347, pooling trick by Crimeacs#8222 (https://twitter.com/EarthML1) and the GUI was made with the help of Abulafia#3734
- BigSleep by lucidrains is a python package that uses BigGAN + CLIP to generate images. You can install the package using
pip install big-sleepcommand. Then creating an image can be done in CLI bydream “a pyramid made of ice”or using python code,
from big_sleep import Imagine
dream = Imagine(
text = "a pyramid made of ice",
lr = 5e-2,
save_every = 25,
save_progress = True
)
dream()- DeepGaze by lucidrains is another python package to generate images. This one uses a combination of CLIP and SIREN (Implicit neural representation network). You can install the package by using command
pip install deep-dazeand then generate image usingimagine “a house in the forest”. It is a CLI base package but provides a lot of parameters to play around with. - Finally, if you want to follow the latest developments and see what cool images others are creating, join #art channel of the discord server of EleutherAI. The good folks at EleutherAI have also created a bot and connected it with a system of 8 GPUs on their channel #the-faraday-cage, where anyone can prompt the bot to create an image using the command
.imagine {your text prompt}.
Prompt engineering
If you observed closely, a lot of the variety in the images is due to the interesting text prompts given as input to the model. Recently people observed that while providing a clear and descriptive prompt generates respectable images, adding a certain prefix or suffix greatly modifies the image or improves the quality. Based on this observation, here are some of the suggestions you could factor into your prompts to generate better images,
- Adding “trending in artstation” or simple “artstation” or “deviantart” to the original prompt will usually lead to better artistic images. This is because CLIP was trained by scraping websites to get image and text pairs, and these are some of the most famous websites where artists share their works. So, interestingly model has learned the correlation of artistic work when the text prompt contains these platform’s mention.
- We can add some suffixes to increase the output quality, like “4k”, “high quality”, “ultrarealistic”, etc.
- We can even add an artist’s name (famous artists) to generate images in their style. For example, the first video was generated by adding the suffix — “by James Gurney”. Further, we can even define the style of painting with “oil painting”, “mural”, etc.
Note, this is not an exhaustive list, our text prompts can include basically any text, so in the end, it's your creativity that matters. Also, people are still figuring out new tricks daily!
Finally, as a side note, if you facing an artist’s block and could not generate interesting prompts, I would suggest using the freely available GPT-J-6B model released by EleutherAI. It is a GPT based text-in text-out model, which you can use to generate lots of prompts. All you need is a brief description and few examples. I used it to generate some of the text prompts that I later used to generate images (talk about inception 🌌). An example is shown below,

References
- Alien Dreams: An Emerging Art Scene By Charlie Snell
- Psychosis, Dreams, and Memory in AI by Henry Wilkin
- Inceptionism: Going Deeper into Neural Networks